So a few months ago I decided to buy an oscilloscope. It’s a nice tool to have, and I certainly would be using it, especially in the insect-camera project.
I wanted connectivity to the computer for sure. But I wasn’t sure I wanted to always have a computer; that is, I prefered a stand-alone device. My bandwidth requirements are not stringent, but, having used two-channel scopes in the past, I wanted to try to get one with four.
In my price range, then, there were really only two options: Tektronix, and Agilent (who now makes the Hewlett-Packard instruments). I had used an HP before (some $15k model) and was surprised to find that, at least at first glance, Agilent has done little to change them: they are still relatively large (especially compared with the Tektronix). (Note: since I bought my scope, it seems that Agilent has changed a few of the lower-end models; moreover, there is no equivalent to the Tektronix model I ended up choosing.) I’ve used plenty of Tektronix scopes, and frankly, the really short depth is a nice feature. If you open one up, you’ll be surprised to find how little is in there (at least in the lower-end models) and that they could have probably made it even smaller had they not made it flexible in terms of accessories.
I settled on the TDS2004B; B meaning it comes with a USB interface (both host and device). The host interface allows you to download pictures and data (I think) directly to a USB memory stick; the device interface is for connecting it to your computer and downloading screenshots and samples that way.
As expected, the unit is very small. It is certainly portable—well, of portable shape. So on with the main points:
Color Display
The display is horrible. First, they put a sticker over it that says one must go to their website to activate the warranty, and, well, it left residue on my screen. Nothing too serious, but at $2k a pop I think anything stupid is serious. But as I said, the display itself is pretty bad. This is the old-school TFT that disappeared off laptops almost as soon as it was invented. It is slow to respond, blurring fast signals, and it has a viewing cone some 20 degrees off vertical (you have to be looking right at it at the right angle to see anything). I was surprised to find I could see it outside in the shade, but only by changing the contrast to zero—that’s right, it’s extremely counter-intuitive, but turning down the contrast makes the display easier to read. It defaults from the factory to invisible. Luckily, a lot of the functions that can make use of a knob for settings do, and a multipurpose knob on the unit has an indicator LED that lights up when you can use it to change a setting.
Portability
This thing may be portable in that it’s small and light, but there’s several problems with that. First, it doesn’t come with a cover. Before the 70’s it seems every instrument had a cover. Now, that apparently is a waste of money. So you’ll be carrying your scope around with all the knobs and the display exposed. Tektronix even sells a soft carrying case so you can see the damage only after you unpack it. I’ve just now discovered that if you’re willing to pay $650, you can buy a hard case for it. It is nothing but a Pelican with custom foam and fits all their oscilloscopes, which means it fits none of them well. Funnies thing is that you’re supposed to put it in the soft case (some $80) before you pack it into the hard case. So you buy a portable scope, but there’s nowhere to put your probes, power cord, or USB cord, and nothing to protect the knobs or the display. A Pelican is really just overkill for storing the instrument. A simple hard plastic cover for the front with a couple of latches for chords would have been nice.
Connectivity
The USB is a joke. Unless you’re going to monitor traffic and write your own driver, all this means is that you’re stuck using their horrible software. I’ve used version 1.5 and am really surprised that they actually update it (v1.6 is out as of now). You can also get “SignalExpress” for use with LabView, and as is common with National Instruments software, the download is an atrocious 300 MB. This “OpenChoice” software is a classic example of programmers being made to waste their time (see below). It serves as the interface on your PC to the device; the functions I’ve used include downloading the currently displayed sample both as a CSV list of values or as a JPG. The JPG is pretty useless, I thought—until I saw the CSV file.
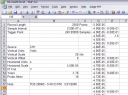
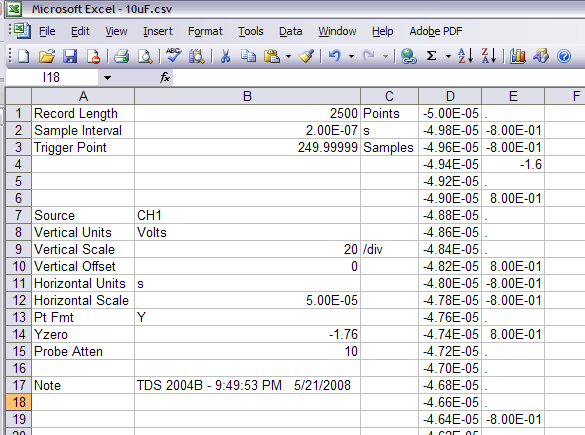
I foolishly thought, “Why would anyone want a bitmap of a plot if one could have the full data?” The reason, as the screen shot of one of the files open in Excel shows, is the extremely awkward and dysfunctional formatting of the CSV files. The presence of text is, of course, a big no-no for directly loading into programs like MATLAB or Tecplot. MATLAB may have an excuse, but Tecplot really should be able to handle whatever you throw at it, but that’s another story entirely. The first thing to notice is that information about the data is stored in the first three columns of the first 17 rows. The fourth and fifth columns are data. Had the data been recorded physically isolated (by lines) from the header information, it would be easy to ignore it or cut it out. Instead, an annoyingly “sophisticated” parser has to be written to extract just the data from the file.
But it doesn’t end there. Obviously when using a spreadsheet program it is easy to plot only the data in certain columns. The problem is that, for some reason, many of the data points that are very close to 0 in magnitude are recorded as a period (“.”). I guess that perhaps it is to distinguish them from a real zero measurement, but I really couldn’t care less. You can’t plot this in Excel, because “.” is not a number.
So the reason for the image capture emerges: if you want to see your data ever again without writing parser scripts, then you better save the image capture for it, too. Too bad the USB interface is one of the slowest I’ve seen—it takes a full two to three seconds to download one “record” from the scope.
The bit about programmers being made to waste their time is in regards to the UI of the software. Unbelievably enough, it uses entirely custom widgets which, of course, do not adhere to Windows standards, such as pressing “TAB” to move to the next field. Even worse, there’s a text field where you can write a comment on your image capture before saving it. The editor does not allow you to type in the middle of the text. That’s right—you can’t move the cursor somewhere and start typing. It doesn’t even overwrite—it simply refuses to accept characters there. The only way to type in the middle of something is to backspace from the end…. There’s a few bugs, too, including the fact that sometimes, when saving a CSV file, it asks for the filename twice (and saves the file twice).
General Design
The scope includes two foldable feet (like some keyboards) to adjust the angle of the unit relative to the surface it’s sitting on. This is absolutely necessary since the display has a very narrow angle of view. The problem is that it only solves the issue in one direction (when the scope is below your eye-level), and the feet are very close to the edges of the unit so if it is not sitting on a surface at most some 2 inches narrower than the scope, they won’t do anything. Many times I’ve found myself stacking the scope on top of other instrument boxes and, well, not many are as wide as the scope. It would be nicer if the feet were closer to the center—or just a huge bar across the whole thing—or, if instead of feet, they made the display sit in a platform so it could be tilted up or down independent of what the scope is sitting on.
The Nice Parts
There are a few nice things about it. The probes it comes with are really nice, and they give you plenty of color-coded wire clips so you can color away all your other probes (if you have any). The probe wires are skinny, though, so there’s few other cables you’ll be able to tag with the clips.
And hell, it’s a nice tool to have. It’s just clear that it suffers from the cheapening disease that plagues everything these days. At least this was a cheap model; these things would be unforgivable with a $10,000 unit.
Conclusion
I don’t have any experience with any of the new scopes from anyone else (Agilent). One thing I would urge is to seriously consider skipping the USB option, unless you think you are really going to need to dump data to a flash drive. Although the specifications are quite cryptic, I believe some of the newer pre-USB models had a serial interface, which is much better in that you can write your own software for it much more easily. Had I known the USB was slow and their software was so miserable I definitely would have gone for it. The best thing to do is to call them. Check the stock on TekSelect, their new-old-stock/refurbished sales central. You should be aware that it doesn’t matter where the instrument was made for, they all have a universal 120/220 power supply. The only thing that changes is the language of the manual (which is downloadable anyway) and the prongs on the power cord (they all use the standard computer cord). You’ll notice the savings on the non-USB models are astounding. In fact, I could have upgraded to the 100 MHz version of this and still saved $300 had I given up the USB—and it would be a new (old stock) unit, not even refurbished! As far as I can tell, to have any connectivity with the pre-USB models, you need something like the TDS2CMAX module, which seems to run around $300. There’s also a TDS2MEM module which adds compact flash card for memory. The TDS series programmer’s manual is the only way to get at what the modules can do, but it certainly seems they can grab images and transfer data. (If the manual link is dead, try this link.) The manual implies it also applies to the B series oscilloscopes; looks like I have some exploring to do.
Well, I just did some exploring, and it seems that the Tektronix scopes, along with Agilent and other instruments comply with the USBTMC protocol (USB instrument control) and there are free libraries available to program such devices through the VISA API. One library is available from Agilent; National Instruments has NI-VISA (I haven’t tried either yet). Beware as it seems there is a pay version as well as a free version of NI-VISA.


{kind=link}